最近、ネットで Qt の禁則処理に関連した話題をいくつか見かけたのですが、Qt はヨーロッパ(ノルウェー)が中心となって開発しているためか、禁則処理のような日本語関連の処理が弱いのではないかと誤解されることがあります。この「Qt in depth」シリーズでは日本語関連の処理や Qt の内部処理など、普段は触れられることのない項目を解説していこうと思います。今回は「Qt の禁則処理」をお届けします。
なお、この記事は Qt 4.7 に基づいて作成しています。Qt の API には出てこない内部処理に関する記事のため、バージョンによっては内容が異なる可能性があることに注意してください。
Qt の禁則処理
禁則処理が何かという詳しい解説は Wikipedia でも見ていただくこととして、Qt ではどのような処理を実装しているのでしょうか。Qt で禁則処理が動いているのを確認するには QTextEdit に適当な文字列を入力してリサイズしてみるのが簡単です。
「Qt をはじめよう! 第14回: GUI デザイナでのレイアウトに慣れよう!」を参考に Qt デザイナで QWidget に QTextEdit を置いてレイアウトを設定した後、プレビューを行うのも手ですし、下記のコードを実行してみるのもよいでしょう。
#include <QtGui>
int main(int argc, char *argv[])
{
QApplication app(argc, argv);
QTextEdit textEdit;
textEdit.show();
return app.exec();
}
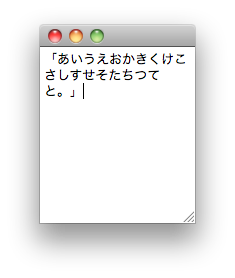
禁則処理が働いていることが確認できたでしょうか。文字間隔の微調整までは行わないものの、行頭禁止文字や行末禁止文字が正しく処理されていることが確認できると思います。
Qt の禁則処理のアーキテクチャ
それでは、Qt ではどのようにして行頭禁止文字や行末禁止文字を決定しているのでしょうか。Qt では HarfBuzz というライブラリを用いて禁則処理を実現しています。より正確には、HarfBuzz を用いてテキストのレイアウトを行っており、その際に禁則処理も行っています。
HarfBuzz
HarfBuzz について簡単に説明しますと、オープンソースのテキストレイアウトエンジンです。元々は FreeType プロジェクトに由来し、Qt や Gtk+ のテキストレイアウト/レンダリングエンジンである Pango で使用され、 HarfBuzz として統一されました。その歴史は "State of Text Rendering" というページが詳しいのでそちらを参照してください。今では Chromium browser でも利用されており、FOSS の標準的なテキストレイアウトエンジンといえるかと思います。
この HarfBuzz ですが、改行位置を決定するアルゴリズムには ”Unicode Line Breaking Algorithm” を使用しています。
Unicode Line Breaking Algorithm
"Unicode Line Breaking Algorithm" は "Unicode Technical Reports" という、 Unicode に関連するドキュメントの一つになります。"Unicode Line Breaking Algorithm" はその Technical Reports の中で "The Unicode Standard Annexes(UAX)" に属しています。UAX は "A Unicode Standard Annex (UAX) forms an integral part of the Unicode Standard" とあるように、Unicode 標準の一部となるドキュメントです。
この "Unicode Line Breaking Algorithm" の中では "Line Breaking Properties" として各文字の属性を、 "Line Breaking Algorithm" としてそのアルゴリズムを、 "Pair Table-Based Implementation" としてその実装例を示しています。
たとえば、句読点である '、'(IDEOGRAPHIC COMMA: U+3001) と '。'(IDEOGRAPHIC FULL STOP: U+3002)」は "Line Breaking Properties" で "Close Punctuation(CL)" 属性を持つ文字の例として示されており、行頭禁止文字として扱われるべきと書かれています。
Qt と Unicode
前述したとおり、HarfBuzz では "Unicode Line Breaking Algorithm" を用いていますが、そのプロパティを含めて全てをその中で実装しているわけではありません。カスタマイズが出来るようにいくつかの定義などは外部から与えてやる必要があります。Qt ではそれらを src/coreilb/tools/ の中の qunicodetables* と qharfbuzz* で行っています。また、 qunicodetables* は "Unicode Character Database" から取得したファイル(utils/unicode/data/ 以下にコピーされています)を元に、util/unicode/ 以下のプログラムを用いて作成されています。この qunicodetables* (と qharfbuzz*)は内部利用のためのクラスであるため Qt API には出てきませんが、"Unicode Line Breaking Algorithm" のだけでなく、"Unicode Bidirectional Algorithm" など、その他のドキュメントもカバーしたクラスとなっています。
実際の禁則処理を行う際には、まず文字列の属性を求めます。この処理は HarfBuzz の HB_GetCharAttributes() を用いて行います。たとえば "「あいうえおかきくけこ。」" という文字列の場合、'「'と'あ'の間は改行禁止(HB_NoBreak)、同様に"こ。」"のそれぞれの文字間は改行禁止という属性が得られます。その他の文字間は全て改行可能(HB_Break)になります。それぞれの属性を考慮した文字区切りを図示したものを下図に示します。
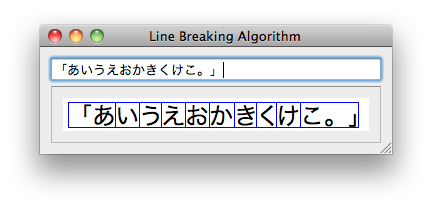
この計算結果を基に、Qt では [qt QTextLayout] クラスが改行位置を計算します。実際にはソフトハイフンの処理も行っているため、若干ややこしくなりますが詳細を知りたい方は src/gui/text/qtextlayout.cpp の layout_helper() などを参照してください。
まとめ
以上、簡単ではありますが Qt の禁則処理がどのようにして実装されているかを説明いたしました。Qt では [qt QTextBoundaryFinder] という単語などの境界を取得するためのクラスでも同様に HarfBuzz と "Unicode Text Segmentation" を用いています。このように Qt の文字列関連の処理は Unicode を元に行っております。興味がある方はそちらも調べていただくと面白いかと思います。
おまけ
HarfBuzz プロジェクトでは現在、HarfBuzz-NG(Next Generation)として、HarfBuzz の再構成を行っております。まだまだ未実装ではありますが、縦書き対応も検討しているようです。将来的に Qt が HarfBuzz-NG に対応することになったときに、Qt での縦書き が実現するかもしれません。
