The cyclomatic complexity is a measurement of the code complexity proposed by Thomas J. McCabe which is often considered as a magic number which allows us to measure the complexity of a program. It is common to say that a function with a cyclomatic complexity higher than 10 is difficult to maintain due to an over-reliance on branches, switch/cases or loops. These functions are often a good candidate for a redesign.
How good is this metric? Would the number of lines of code give us the same result? If that were true, it would make more sense to the simpler metric since everybody intuitively understands it.
To answer this question, I will expose how to compute it and then analyze some properties.
How to compute the cyclomatic complexity?
The formula of the cyclomatic complexity of a function is based on a graph representation of its code. Once this is produced, it is simply:
M = E - N + 2
E is the number of edges of the graph, N is the number of nodes and M is McCabe's complexity.
To compute a graph representation of code, we can simply disassemble its assembly code and create a graph following the rules:
- Create one node per instruction.
- Connect a node to each node which is potentially the next instruction.
- One exception: for a recursive call or function call, it is necessary to consider it as a normal sequential instruction. If we don't do that, we would analyze the complexity of a function and all its called subroutines.
Let us have a try with a small sample:
#include <stdio.h>
int main( int argc, char *argv[] )
{
if ( argc > 1 )
{
fprintf( stderr,
"This program does not accept arguments!\n"
);
return 1;
}
else
{
fprintf( stdout, "Hello world!\n" );
return 0;
}
}
The assembly output is:
%struct._IO_FILE = type { i32, i8*, i8*, i8*, i8*, i8*, i8*, i8*, i8*, i8*, i8*, i8*, %struct._IO_marker*, %struct._IO_FILE*, i32, i32, i64, i16, i8, [1 x i8], i8*, i64, i8*, i8*, i8*, i8*, i64, i32, [20 x i8] }
%struct._IO_marker = type { %struct._IO_marker*, %struct._IO_FILE*, i32 }
@stderr = external global %struct._IO_FILE*, align 8
@.str = private unnamed_addr constant [41 x i8] c"This program does not accept arguments!\0A\00", align 1
@stdout = external global %struct._IO_FILE*, align 8
@.str.1 = private unnamed_addr constant [14 x i8] c"Hello world!\0A\00", align 1
; Function Attrs: nounwind uwtable
define i32 @main(i32 %argc, i8** %argv) #0 {
%1 = alloca i32, align 4
%2 = alloca i32, align 4
%3 = alloca i8**, align 8
store i32 0, i32* %1
store i32 %argc, i32* %2, align 4
store i8** %argv, i8*** %3, align 8
%4 = load i32, i32* %2, align 4
%5 = icmp sgt i32 %4, 1
br i1 %5, label %6, label %9
; <label>:6 ; preds = %0
%7 = load %struct._IO_FILE*, %struct._IO_FILE** @stderr, align 8
%8 = call i32 (%struct._IO_FILE*, i8*, ...) @fprintf(%struct._IO_FILE* %7, i8* getelementptr inbounds ([41 x i8], [41 x i8]* @.str, i32 0, i32 0))
store i32 1, i32* %1
br label %12
; <label>:9 ; preds = %0
%10 = load %struct._IO_FILE*, %struct._IO_FILE** @stdout, align 8
%11 = call i32 (%struct._IO_FILE*, i8*, ...) @fprintf(%struct._IO_FILE* %10, i8* getelementptr inbounds ([14 x i8], [14 x i8]* @.str.1, i32 0, i32 0))
store i32 0, i32* %1
br label %12
; <label>:12 ; preds = %9, %6
%13 = load i32, i32* %1
ret i32 %13
}
We can then create a graphical representation of the assembly instruction flow:
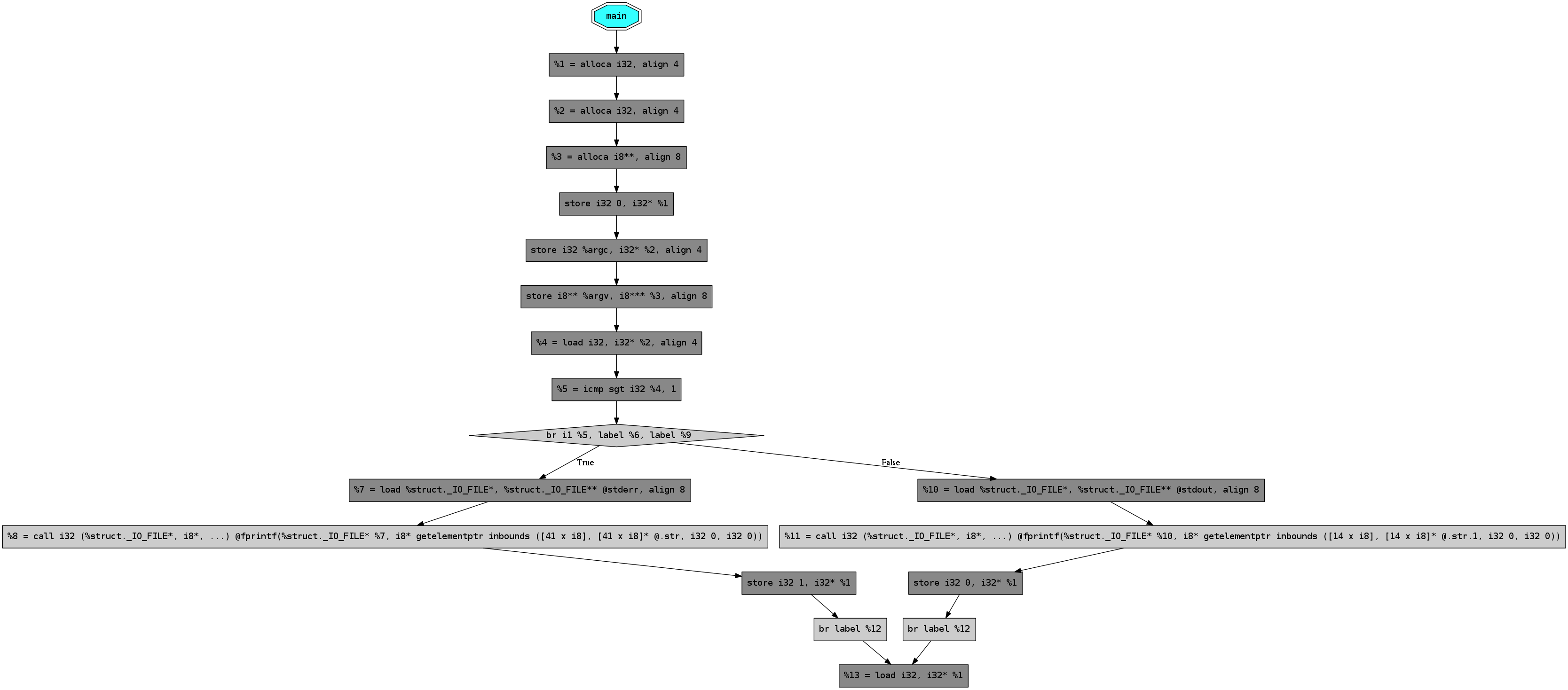
We have 19 nodes and 19 edges, McCabe's complexity is then:
M = 19 - 19 + 2 = 2
Properties
The McCabe's formula 'E - N + 2' in the first approach strange because adding or subtracting two measures (here number of nodes and number of edges) expects that they have the same units. That's why a distance is never added to a duration in physic but in most of the cases multiplied or divided.
But, in the case of McCabe, this formula simply the number of independent paths that exist between the input of the function and its output. For our example, the cyclomatic complexity is 2: one for the path for the 'if' branch plus one for the path of the 'else' case.
This has also a number of implications:
- McCabe is independent to the number of source lines of a function: it does not matter how many statements are present in the code but how many branches are into it.
- The metric is completely independent of the code style. Reformatting the code does not affect it. This is a big difference to the common line of code metric.
- The metric has a linear grow with the function complexity. For example, adding a 'if ( ... ) ... else ...' statement somewhere in a function increments the metric by one. It does not matter if the selection statement is nested or at the beginning of the function and it does not grow exponentially.
- McCabe is easy to interpret for a single function. But, its computation for a source file, a class or an application is difficult to interpret. The reasons for this is that the function call is not represented in the flow diagram. The McCabe metric is computed independently for each function and it is as if there are interactions between the functions present in the source code.
- McCabe is not adapted to measure the complexity of the software architecture. Or, to say it differently, it does not work on a complex C++/C# design pattern which splits the complexity over several classes.
- And of course, like for all metrics, McCabe's measure is only of code complexity and not the complexity of the data structures.
Analysis of some results
Computing the cyclomatic complexity on some samples allows us to better identify how source code affects the metric.
Here are some generic rules:
- Adding an 'else' block to a 'if' statement does not affect its metric (see sample I1 and I2).
- The complexity of a boolean expression has no impact on the code metric (see sample I2 and I3). McCabe can be compared to the decision coverage for which it is important to track if a complete boolean expression was true and false.
- If a function is composed of two blocks, the cyclomatic complexity of the function is the sum of the complexity of each of it. If we take I2 and add and 'if' statement (see sample I4), the complexity is incremented because a single 'if' statement has a complexity of 1.
- It does not matter if some code is composed of two sequential or two nested parts. I4 and I5 illustrate this: cascading 'if' statements have the same effect on the metric as sequential if statements.
- All loops are equivalent to an 'if' statement (see L1, L2, L3).
- Adding a 'case' to a 'switch' statement increments the cyclomatic complexity. (see S1 and S2)
| # | Code | McCabe |
|---|---|---|
| I1 |
void foo( int a ) {
if ( a )
return ;
else
return ;
}
|
2 |
| I2 |
void foo( int a ) {
if ( a )
return ;
}
|
2 |
| I3 |
void foo( int a, int b ) {
if ( a && b )
return ;
}
|
2 |
| I4 |
void foo( int a, int b ) {
if ( a )
return ;
if ( b )
return ;
}
|
3 |
| I5 |
void foo( int a, int b ) {
if ( a )
if ( b )
return ;
}
|
3 |
| I1 |
void foo( int a ) {
while ( a )
a-- ;
}
|
2 |
| I2 |
void foo( int a ) {
do
a-- ;
while ( a );
}
|
2 |
| I3 |
void foo( int a ) {
for ( int x = 0; x < a; x++ )
foo() ;
}
|
2 |
| S1 |
void foo( int a ) {
switch ( a )
{
case 1:
return ;
}
}
|
2 |
| S2 |
void foo( int a ) {
switch ( a )
{
case 1:
case 2:
return ;
}
}
|
3 |
Conclusion
McCabe's cyclomatic complexity is a simple and intuitive metric that allows us achieve reliable results at the function level. It does not cover all kinds of software complexity but it allows us to clearly identify functions with a lot of loops, selection statements and switch/cases. That's why we have also included it in Squish Coco v4.2 and above.


