Works for me! Did you ever hear yourself uttering those words, or maybe you heard them from a colleague? Tests which work on one system may fail on another. This can happen for many reasons: the application under test (AUT) depends on the operating system on which it is executed. The test case code depends on the application build being tested. Or test cases depend on each other, and the order in which they are executed is important.
The last issue can become a real problem: as test suites grow, it can happen that implicit dependencies are established between test cases. In this article, we'll discuss where dependencies between test cases come from, why they are bad, and how to detect them using froglogic Squish.
Causes Of Implicit Test Case Dependencies
Dependencies between test cases may have been introduced intentionally. For instance, when multiple test cases attach to and detach from a running application (using the attachToApplication script call), it might improve test execution speed to not reset the application state after every test case. Instead, one might decide to have a sequence of subsequent test cases reuse the state of the application. That way, subsequent test cases don't have to start 'from scratch' but rather can perform a few additional steps.
A dependency between two or more test cases might also have been created unintentionally though. One test case might have created a test data file and leaves it behind because it neglects to clean up. A next test case might then reuse that test data file, silently asserting that it always exists. As long as the test cases are executed in order (e.g. because the test suite is executed as a whole), this dependency can remain unnoticed for a long time because everything seems to be fine.
Why Are Test Case Dependencies A Problem?
Dependencies between test cases are problematic for a number of reasons such as
- In case a test case fails, it's not possible to run just the failing test case in isolation as part of reproducing and debugging the issue. Instead, an (often unknown) number of preceding test cases needs to be executed as well. This can greatly slow down tracing down the cause of the issue.
- Reusing test code in multiple test cases is more difficult. If a test case implicitly assumes that another test case was run earlier, then this assumption is not expressed anywhere within the script code. As a consequence, factoring a portion of the test code into a shared function may not make that code reusable since the code may assume that some other code in another test case to execute first. This an assumption which may not be satisfied when calling the code from another test case.
- Refactoring test code is error prone. Since other test cases may depend on the behaviour of a given test case, refactoring it may suddenly cause other test cases to fail. This is hard to debug since the refactoring was assumed to not have any functional impact based on reading the test script code.
Hence, it's desirable to identify and eliminate implicit assumptions and interactions between test cases.
How To Identify Test Case Dependencies
A very simple and effective way to identify cases in which a test case 'A' is required to precede the execution of a test case 'B' is to try it the other way round: first 'B', then 'A'. Extrapolating this idea to a test suite of multiple test cases means that the test cases are shuffled and thus executed in a different order. By using a different order on every test execution, you're more likely to identify and thus weed out any interactions between test cases.
However, once a dependency is found, it is important to be able to re-run the test cases in the problematic order. Hence, the ordering should not be totally random but deterministic and reproducible at will.
Randomising Test Case Execution Order with Squish
Squish allows executing the test cases of a test suite in a random order by accepting a --random argument when invoking the squishrunner command line tool. The command line documentation explains:
The
--randomoption is for executing test cases in random order. The used sequence number is printed in the report as log message. If it is necessary to reproduce a specific order the sequence number can be given as parameter to the--randomoption. This can be used to reproduce a failure that occurs during random test execution. A sequence number of 0 indicates that a new sequence number is generated. It gives the same behaviour as when the value for the option is omitted.
Here's how it works in practice:
When executing an example test suite containing five test cases on the command line by running
squishrunner --testsuite suite_examplesuite --reportgen html,/tmp/firstrun
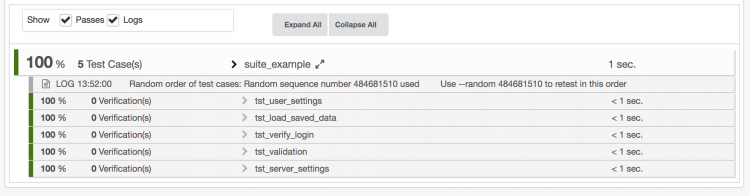
We get an HTML report showing that the test cases have been executed in a fixed order:
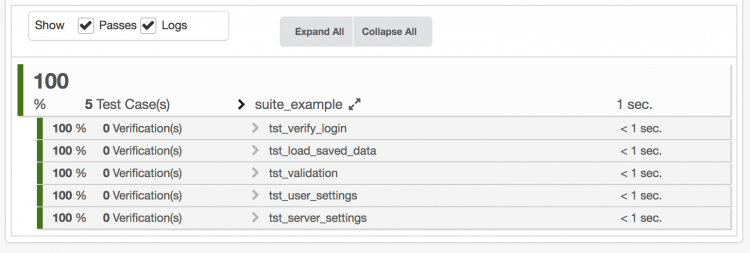
When extending our command line using the --random argument as follows:
squishrunner --testsuite suite_examplesuite --reportgen html,/tmp/secondrun --random
A slightly different report is generated:
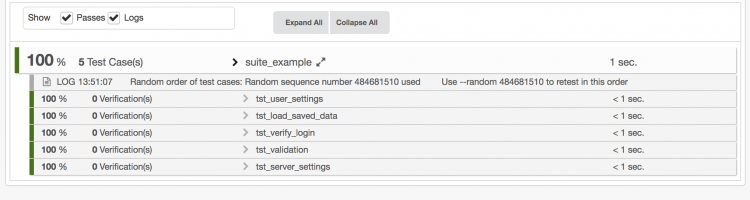
Note how the test cases are executed in a different order, and an additional log message is printed given the unique identifier for the particular random number. This number can be passed to the --random switch to reproduce the order:
squishrunner --testsuite suite_examplesuite --reportgen html,/tmp/thirdrun --random 484681510
As expected, the test cases are executed in the same order as before: