Locating a software failure can be a tenuous and a time intensive operation due to the fact of the explosion of the source code size and their test suite. Also the complexity of some software imposes an organization in which the test team is separated from the development teams. In this condition, it is generally difficult to find with a simple test report the code parts responsible for a bug. A common way to facilitate the correction is to provide additional information like code dumps, execution traces, screen shots...
Code coverage metrics can also be provided. This metrics consists of recording if a source code item was executed or not. This is less precise that execution traces, but it has the advantage that this information is always available for the project on which it is also used to measure the quality of the code.
One way to use this information, is to compare a failed with a passed test. As explained in a previous post, the difference in the executed code can give a hint to the location of the bug. But on huge project with a lot of tests it is difficult to choose the pertinent tests and there is no guarantee that the failed test is executing more code as the passed tests.
A better approach is to process all coverage data globally with an algorithm which scans the execution of all passed and failed tests. I present here the philosophy of it as implemented in Squish Coco v3.4.
How does it work?
The Concept
Instructions in a program are have a strong dependency and removing or moving an instruction generally modifies its behavior. completely. Some groups of instructions cannot be dissociated when observing the code coverage. This is the case for blocks of sequential instructions. Instead of analyzing each the instrumented line separately we group them together into classes of equivalence. Two instrumented lines are considered equivalent if they are executed by the same set of tests. Grouping the instrumented lines together does not only permit to better present the result of computation, but also permits to consider it as independent regarding the theory of the probability.
To locate a bug, we simply simulate the behavior of a human been searching for a single error present in the source code through a stochastic process that goes from source code lines to source code lines. After each step the process tries to jump to the next better error candidate. After an infinite time, we can then look on the probability that a source code line was chosen as the best location of the failure.
To initiate the process, any covered source code line should be selected. Then we select another instrumented source code line with the following rules:
- Choose any test execution which is covering the current line.
- Then choose the next source line candidate as followings:
- If the test was passed, the failure is not expected to be in the source lines executed by the choose test. So select any instrumented line that is not executed by this test.
- If the test was failing, select any source code line that is executed by this test.
We repeat this process until a set of pertinent source code lines are identified.
A trivial sample
Let have a try with a trivial sample, an inverter code:
[code language="cpp" gutter="false"]float inv( float x )
{
if ( x != 0 )
x = 1 * x ; // <- here is the bug
else
x = 0;
return x;
}
[/code]
The bug itself is easy to understand, a multiplication is used instead of a division.
Our test suite is:
| Name | Test | State |
| INV(0) | inv(0) == 0 | Passed |
| INV(1) | inv(1) == 1 | Passed |
| INV(2) | inv(2) == 0.5 | Failed |
| INV(3) | inv(3) == 0.3333333 | Failed |
| INV(4) | inv(4) == 0.25 | Failed |
There is one aspect which makes the comparison of the test execution difficult: the test INV(1) has exactly the same coverage as the failed tests INV(2) to INV(4). This makes a simple comparison of the executions unusable.
Let's apply the bug location algorithm step by step.
First, it is not possible to dissociate the line 'if ( x != 0 )' and 'return x;' with a test. If one of this line is executed, the other one is also. We group it together and consider as one single line. This means that if we estimate that these lines are a good error candidate, we cannot determinate which of this line is responsible of the bug. To simplify the explanation, we omit now the return statement.
Let's start now by selecting randomly the source code line 'if ( x != 0 )' as a bug location candidate. The we search the list of tests executing it and select 'INV(2) randomly:
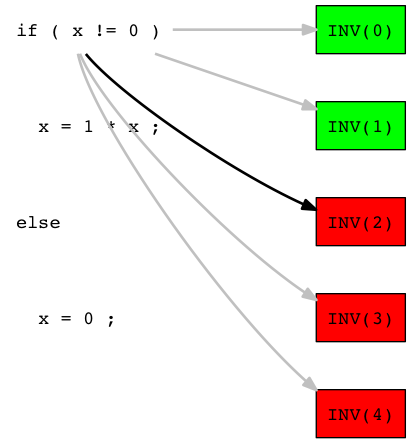
The test 'INV(2)' is failing, so we suppose that a source code line executed is responsible of the error. We then select then as the next bug location candidate the line 'x = 1 * x' which is executed by 'INV(2)':
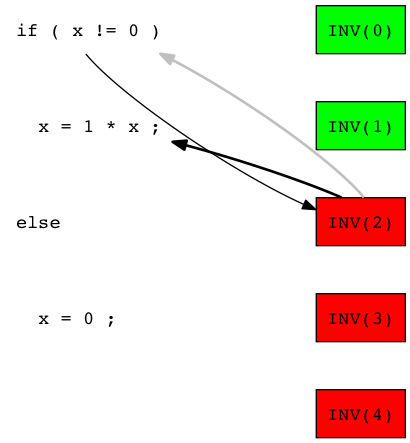
We then randomly select the test 'INV(1)' in the set of tests executed by the line 'x = 1 * x' ('INV(1)', 'INV(2)', 'INV(3) and 'INV(4)'):
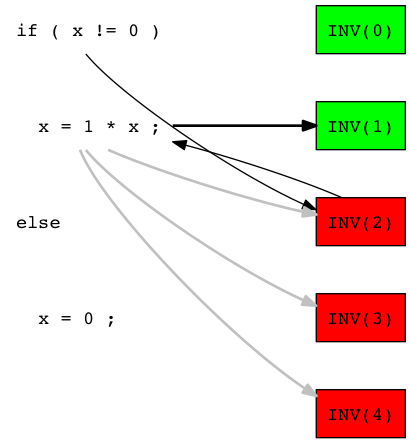
The test 'INV(1)' is passed, so we suppose that a source code line which is not executed by this test is responsible of the error. We select then 'x = 0;' as next candidate:
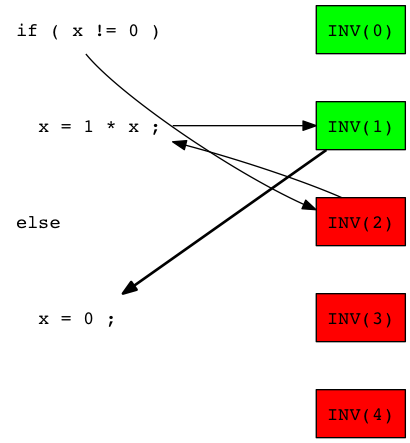
We then keep on iterating and compute the probability that a source line is chosen as bug location candidate:
| Line | Probability |
| 'x = 1 * x' | 0.528 |
| 'if ( x != 0 )' | 0.283 |
| 'x = 0;' | 0.188 |
As expected, the line 'x = 1 * x' has a higher probability of having a bug.
(Note: for a better precision and a better performance, Squish Coco compute directly the probabilities and does not use a sampling method.)
A test on a real sample
Squish Coco's parser sample is a small calculator written in C++ which permits to add, subtract, multiply or divide integer or floating point number. It supports the engineering syntax for numbers but does not check their syntax. 1E3, 1E+3 or 1.0E3 are all numbers equivalent to the number 1000. But it does not generate an error when entering the invalid number 1E+.
Here is the output:
$ ./parser
Enter an expression an press Enter to calculate the result.
Enter an empty expression to quit.> 1E+3
Ans = 1000
> 1E+
Ans = 1
>
To identify the source code line responsible for this issue we simply create few new unit tests:
| Test | Expected Output | Status |
| 1.1e+ | Error message | Failed |
| 1.1e+1 | 11 | Passed |
| 1.1e-1 | 0.11 | Passed |
| 1.1e1 | 11 | Passed |
Each of these are quite similar because they are simply different floating point numbers. But due to the fact that they are not all failing, they allow the bug location algorithm to better identify which source code parts have a high probability to contain a bug.
The result can be viewed with CoverageBrowser:
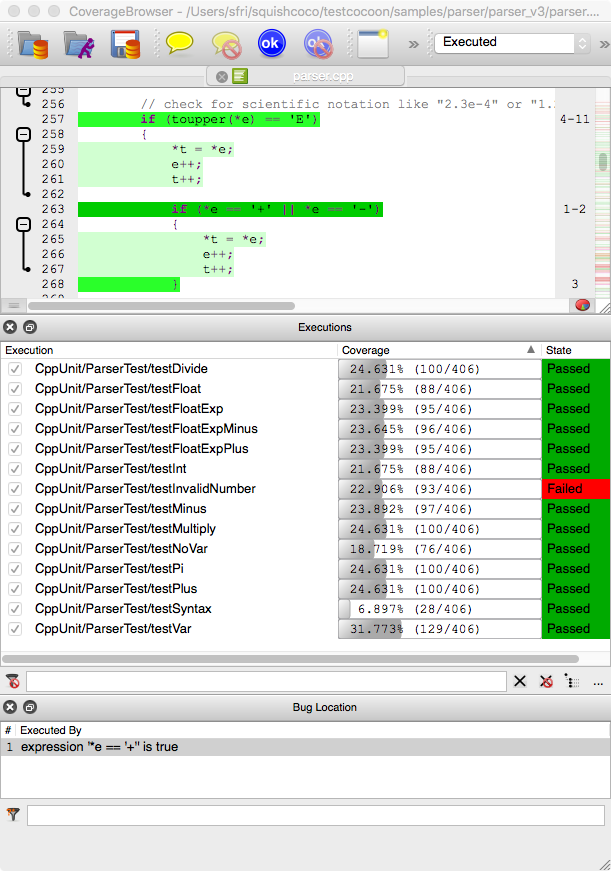
It is corresponding to the source line which is handling the '+' or '-' sign after the letter 'e' or 'E'. This is the correct location after which we can generate an error message if a required digit is not present.
Conclusion
Squish Coco offers now a new methodology based on the code coverage analysis to investigate issues.
If we compare it to a debugger, there may be less no variable values visible but less knowledge of the software architecture is required.
Only a suitable set of tests for the product are required to:
- find candidate places on which a developer can set a breakpoint to investigate an issue.
- find the right developer able to investigate an issue by combining the information provided by the repository ('git blame' permits to compute who was modifying a source code line) and the bug location.
- perform a post-mortem analysis for issues which are difficult to reproduce.


