In 2023, the way software is developed has changed. Forever. There is no turning back.
Traditionally, software developers asked their team colleagues or searched on Internet resources, such as Stack Overflow, when they needed help to create new code or learn a new programming language.
Already in the past, Integrated Development Environments (IDE) could provide auto-complete functionality for code and code snippets such as elements andproperties. However, coding assistants powered by Generative AI have taken auto-completing of code to a whole new level creating entire functions, test cases, and code documentation. Furthermore, coding assistants such as GitHub Copilot create new code on request through natural language prompts entered as comments in the code.
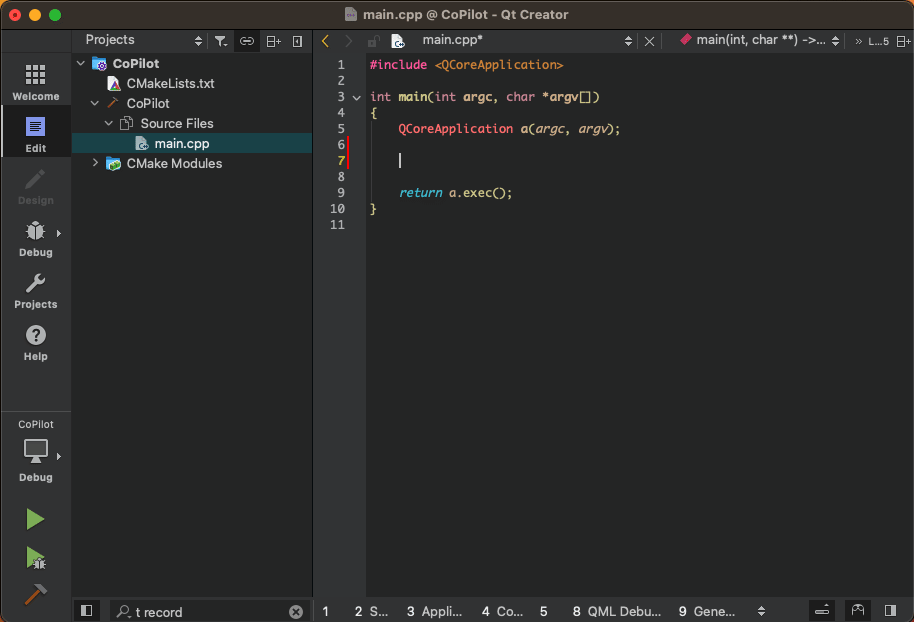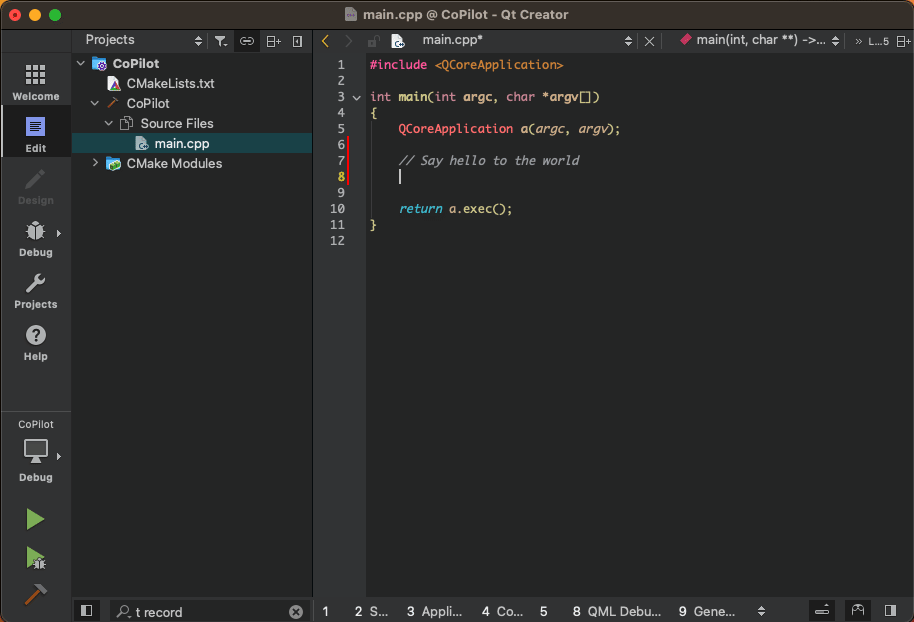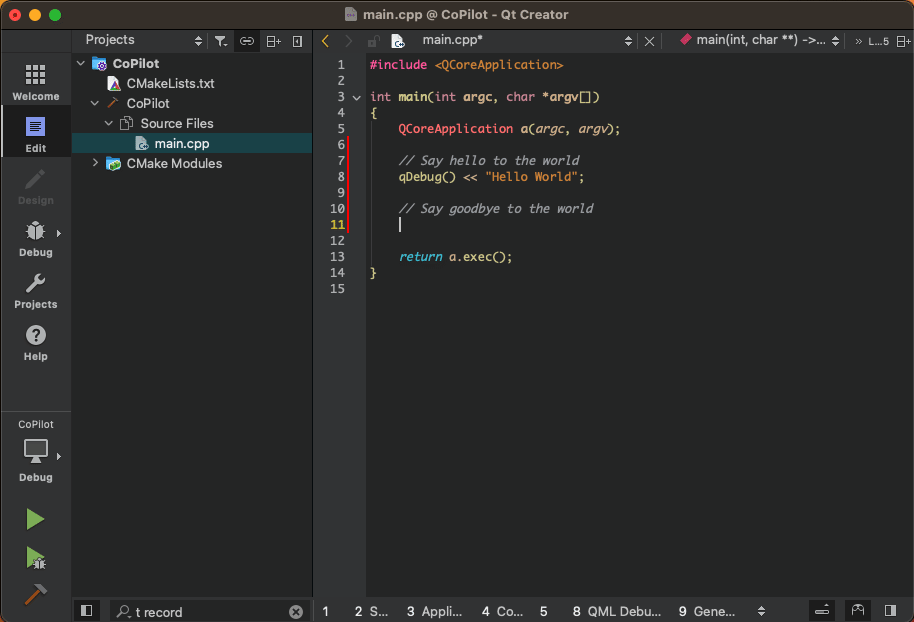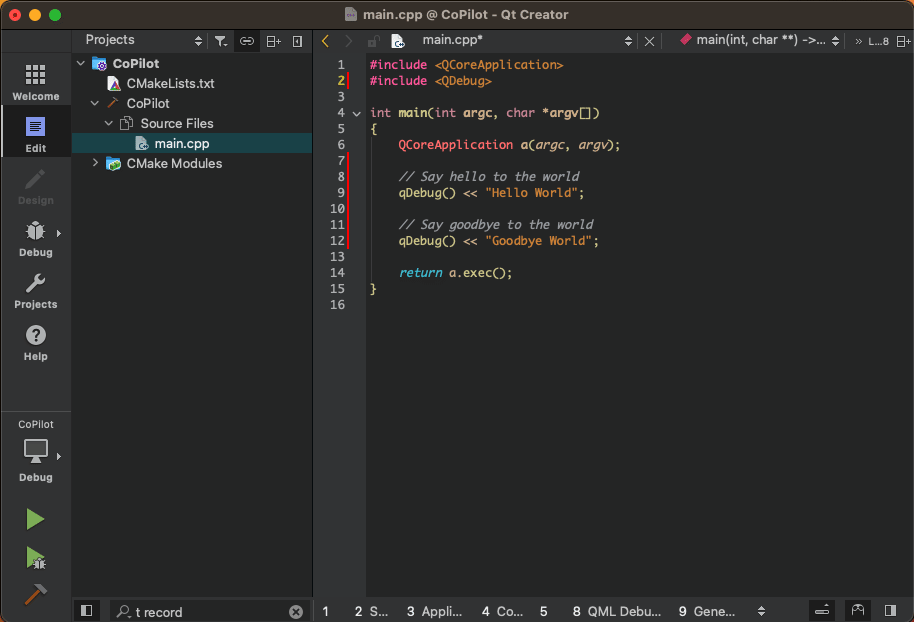
Illustration: Code generation in Qt Creator through GitHub Copilot integration
These game-changing capabilities reduce the time developers spend on boilerplate and repetitive code, but also how they get help. Peer-to-peer support services such as Stack Overflow can feel the change.
With the release of GitHub Copilot and ChatGPT, developers are less often looking for content on Stack Overflow in 2023. In August 2023, Stack Overflow wrote: “…in April of this year, we saw an above average traffic decrease (~14%), which we can likely attribute to developers trying GPT-4 after it was released in March… This year, overall, we're seeing an average of ~5% less traffic compared to 2022… The surge in generative AI, like the rise of any other disruptive technology, should cause us to reflect, challenge, and question how we measure success.”
Nevertheless, coding assistants will evolve significantly in the coming years. Let me highlight three things that will influence coding assistants in the future.
Regional Regulations for Generative AI are forming
Which suggestions coding assistants are allowed to make will change due to regulatory activities. While there doesn't seem to be a global regulative framework for Generative AI on the horizon, we are likely to end up with regional legal frameworks for data privacy, such as the European General Data Protection Regulation(GDPR), the US Privacy Act, or China's Personal Information Protection Law (PIPL).
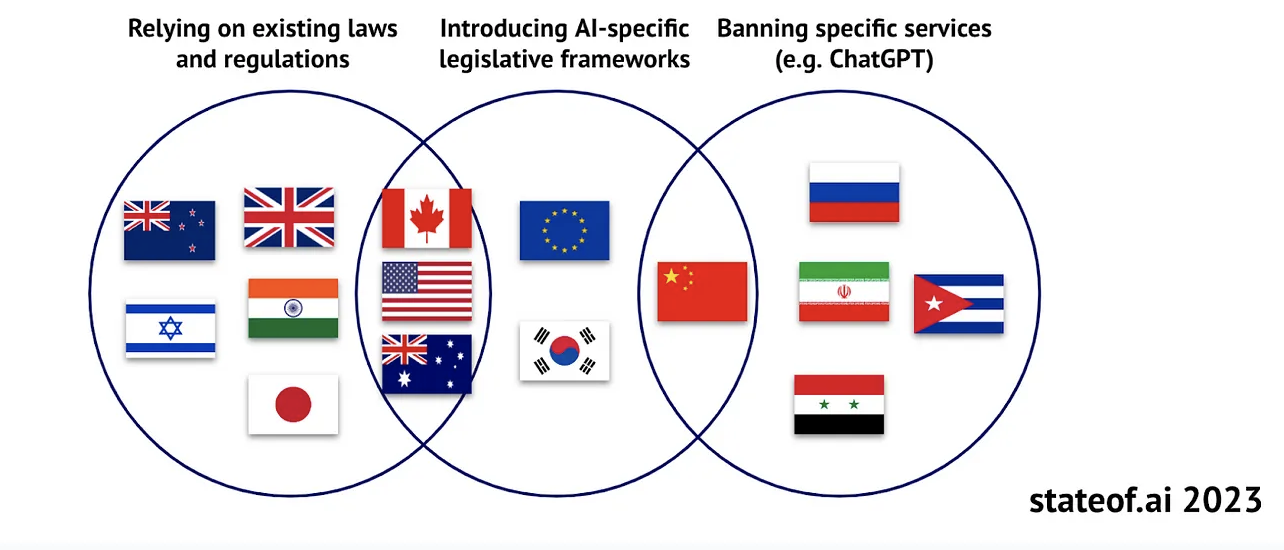
Source: State of AI 2023 report by Othmane Sebbouh, Corina Gurau and Alex Chalmers
Once the regulations on Generative AI are decided in major economic areas such as Europe and the US, then coding assistants are likely to adopt those through more transparency on which training data has been used and with tighter guardrails on which code is being suggested.
Industry-specific Large Language Models are emerging
I believe that we will see industry-specific LLMs emerge during 2024 that power code generation for professional developers in the enterprise segment. Why? Because industry-specific LLMs can focus on doing specific things very well instead of being good at everything.
The most known coding assistant, the GitHub Copilot, is powered by the OpenAI Codex LLM. The OpenAI Codex is a descendant of OpenAI's GPT-3 model, optimized for code generation use cases. The GPT3 LLM was released in 2020, meaning that the code suggestions are based on training data that is three years old or more. While wine might improve over time, three years in software development are huge. Because my job is to make software development for cross-platform applications easier, I am quite worried about the relevance of training data used for the OpenAI Codex LLM. When the OpenAI Codex LLM was trained, the Qt 6.2 LTS release - not to mention the Qt 6.5 LTS release - didn’t exist. This is obvious whenever developers prompt to generate code for modules in the Qt 6 release series. I guess – without having any insider knowledge - that OpenAI will publish a newer version of the OpenAI Codex during 2024, but will it know the Qt 6.8 LTS release? I doubt it.
Large Language Models are costly to train due to the massive data set. Therefore, the training occurs less frequently than innovations in UI and application frameworks. There are ways to complement the knowledge of LLMs, such as Retrieval Augmented Generation tapping into fresh information resources. Still, these don't change the fundamental issue that the deep learning of LLMs is only substituted with fresh knowledge from dedicated resources. The relevance of training data is one reason I believe smaller and industry-specific LLMs will emerge. Industry-specific LLMs require less training data than general-purpose LLMs and, therefore, are easier and cheaper to keep up to date.
Transparency will take priority in selecting LLMs for code generation in enterprises
Enterprises can only use code when they know where it is from and what licenses are attached to it. Even when coding assistants make a point that code suggestions are created from scratch, it is still possible to contain the same code as the training data. GitHub writes in its FAQs: “GitHub Copilot generates new code in a probabilistic way, and the probability that they produce the same code as a snippet that occurred in training is low.” Is a low probability enough for commercial enterprises? A single copyright infringement might mean software vendors must stop distributing their products. It gets even worse if we consider a digital hardware product without over-the-air software update capabilities. Such a product would need to be recalled in a worst-case scenario. Hence, businesses demand to know where code suggestions come from and whether they infringe on other people's IPRs. Transparency on the origin of training data is one way to solve this issue. While OpenAI does not clearly state what code it has used to train the model, it becomes evident from simply trying it out that it must have scanned Qt framework repositories on GitHub extensively. But whether the code suggestions include “copies” of code with permissive or non-permissive licenses remains a mystery to the developer.

Coding assistants might offer ways to remove suggestions that equal public code before suggesting them to the developer or use only an LLM based on permissive training data—however, a lot of knowledge of what good code is lost. A coding assistant that has seen little professionally developed code for embedded devices or no code from the Qt 6 series framework repositories is great for developers new to C++, but senior Qt application developers might expect more. Fortunately, GitHub is working on a feature that provides references for suggestions that “resemble public code” (in GitHub repositories) to create more transparency.
Code generation LLMs, such as the open-source StarCoder LLM, are more transparent. One can check whether repositories from a particular GitHub user have been used to train the model. For example, the StarCoder LLM has used only three Qt framework repositories with MIT licenses but excluded all other libraries.
Due to regulatory pressure or company risk management, knowing that the originator of the training code has given permission to be used to train a Large Language Model and under which conditions will play a bigger role in the future. Therefore, enterprises might consciously choose smaller but transparent language models as a foundation for code generation.
The Qt Creator IDE has a ready plug-in to the GitHub Copilot supporting a variety of coding assistant use cases. If you want to know more about using GitHub Copilot with the Qt Creator, check for more information here.
PSC: No generative AI was used writing this blog post...


